Vorhersage des Entlassungsortes bei Herzinsuffizienz-Patienten

Abstrakt: Herzinsuffizienz ist eine der häufigsten Ursachen für Krankenhausaufenthalte und Wiederaufnahmen in US-Amerikanischen Krankenhäusern. Das führt zu einem erhöhten medizinischen Risiko und höheren Kosten bei betroffenen Patienten. Der Entlassungsort steht dabei in engem Zusammenhang mit dem Risiko einer Wiederaufnahme und der Sterblichkeit. Die Vorhersage des voraussichtlichen Entlassungsortes ist daher eine entscheidende Aufgabe (sowohl für die Patienten als auch für die Einrichtungen). Bisher hat sich die Arbeit zur Klassifikation von Patientenentlassung auf den "Zustand" der Patienten am Ende der Behandlung beschränkt. Der eigentliche Behandlungsprozess selbst wurde bislang noch nicht berücksichtigt. In dieser Arbeit werden Methoden der "Process Outcome Prediction" verwendet, um den Entlassungsort von Patienten mit Herzinsuffizienz vorherzusagen, indem verschiedene Stationsaufenthalte und medizinische Messwerte während des Behandlungsprozesses einbezogen werden. Die vorliegende Forschung und die dazugehörige Publikation zeigen, dass mit Hilfe von Convolutional Neural Networks (CNNs) eine Genauigkeit von 77 % bei der Klassifikation des Entlassungsorts von Herzinsuffizienz-Patienten erreicht werden kann. Das Modell wurde auf dem MIMIC-IV-Datensatz zu Krankenhausaufenthalten in den USA trainiert und evaluiert. Unsere Forschung zeigt auf, dass mit Hilfe von Convolutional Neural Networks (CNNs) eine Accuracy von 77 % bei der Klassifikation des Entlassungsorts von Herzinsuffizienz-Patienten erreicht werden kann. Das Modell wurde auf dem MIMIC-IV Datensatz trainiert und evaluiert.
Kontext: Die im Folgenden beschriebene Forschungsarbeit wurde im Rahmen des Seminars „Advanced Topics in BPM Research“ im Zuge meines Masterstudiums am Hasso-Plattner-Institut durchgeführt – gemeinsam mit Maximilian König, unter der Betreuung von Jonas Cremerius und Prof. Dr. Mathias Weske.
Datensatz: Der MIMIC-IV Datensatz (Medical Information Mart for Intensive Care (MIMIC)1) diente als Grundlage der Vorhersage des Entlassungsorts. Der Datensatz ist öffentlich auf PhysioNet verfügbar (zugriffsbeschränkt gemäß Datenschutzbestimmungen – siehe Lizenz. Der Datensatz enthält Informationen zu über 40.000 Patienten, die zwischen 2008 und 2019 im Beth Israel Deaconess Medical Center in Boston, Massachusetts, behandelt wurden.
Der MIMIC-IV Datensatz umfasst 35 Tabellen und umfasst unter anderem folgende Informationen: demographische Informationen wie Alter und Familienstand, durchlaufene Krankenhausstationen und auf den Stationen verabreichte Medikamente. Zudem gibt es diagnosebezogene Informationen - darunter ICD-Codes (International Classification of Diseases), DRG-Codes (Diagnosis Related Groups) und Laborwerte aus Tests wie Hämoglobin, Kreatinin und Harnstickstoff.
Nach Vorverarbeitung des Datensatzes ergibt sich eine "drei-dimensionale" Datenstruktur (für verschiedene Patienten, über unterschiedliche Zeitpunkte hinweg und mit mehreren Merkmalen.
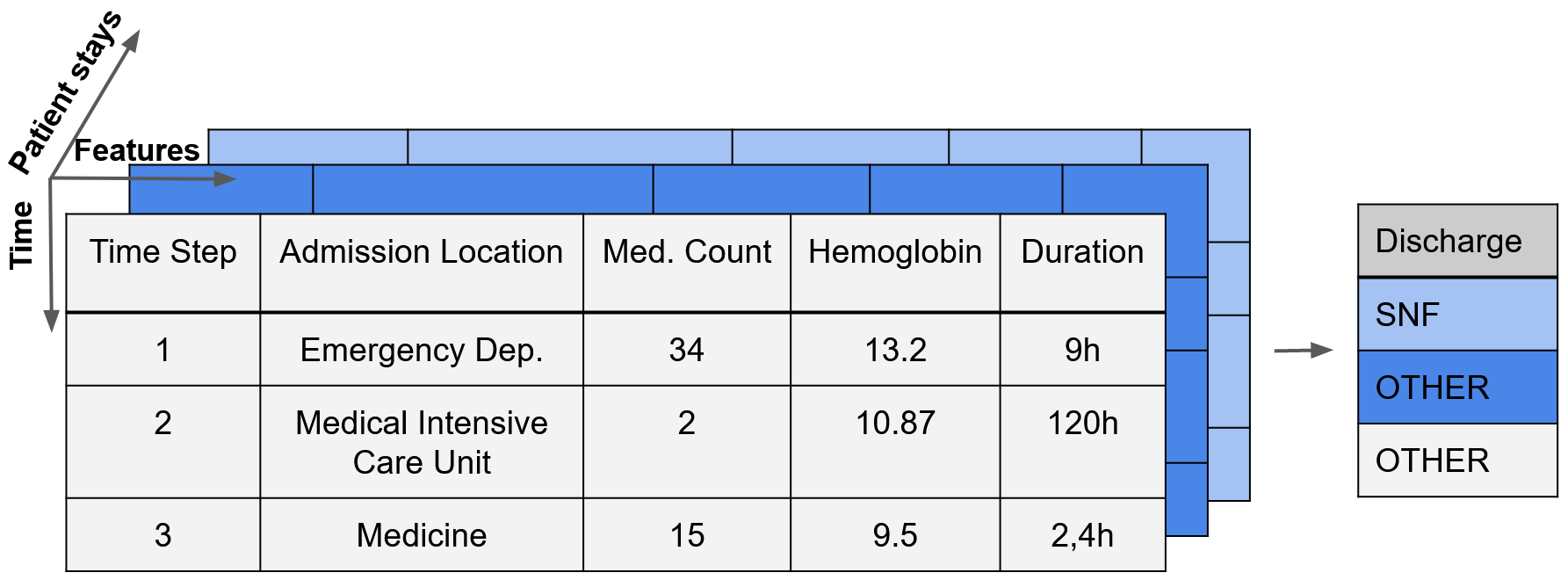
Process Outcome Prediction (Vorhersage von Prozessergebnissen): Business Process Management (BPM) umfasst Konzepte, Methoden und Techniken zur Unterstützung des Entwurfs, der Verwaltung, Konfiguration, Ausführung und Analyse von Geschäftsprozessen2.
Das Business Process Monitoring ist ein Teilbereich des Business Process Managements und ermöglicht die Analyse von Ereignissen, die während der Prozessausführung auftreten. Dadurch lassen sich Einblicke in den gesamten Prozess gewinnen und Ansätze zur Prozessverbesserung identifizieren.
Ein Teilgebiet des Business Process Monitoring ist das Predictive Business Process Monitoring, das darauf abzielt, zukünftige Zustände oder Ausgänge laufender Prozessausführungsinstanzen vorherzusagen (basierend auf bereits ausgeführten Aktivitäten und durch auf historischen Daten gelernte Muster).
Eine in den letzten Jahren in diesem Bereich entwickelte Technik ist die Vorhersage von Prozessergebnissen (Process Outcome Prediction). Laut Teinemaa et al. lässt sie sich definieren als die Klassifikation jeder laufenden Prozessinstanz in eine gegebene Menge möglicher kategorischer Ausgängen3.
Vorteile einer frühen Vorhersage von Prozessausgängen während der Prozessausführung ist eine bessere Planbarkeit und Möglichkeit während der Ausführung, Entscheidungsprozesse zu optimieren4.
Convolutional Neural Networks: Convolutional Neural Networks (CNNs) sind tiefe neuronale Netze, die häufig für Sequenz-Klassifikationsaufgaben und die Process Outcome Prediction eingesetzt werden4 5 6. Ursprünglich wurden CNNs vor allem im Bereich der Mustererkennung, insbesondere bei Computer-Vision-Aufgaben wie Bildanalyse bekannt. Eine CNN-Architektur besteht im wesentlichen aus drei Komponenten: Convolutional Layers, Pooling Layers und Fully-Connected Layer. Convolutional Layer führen "convolutions" mit Kerneln verschiedener Größe durch, um "abstrakte" Merkmale aus den Daten zu extrahieren und gleichzeitig die Dimensionalität zu reduzieren. Pooling Layer dienen zum Downsampling, um die Komplexität für nachfolgende Layer zu verringern. In Fully-Connected Layers ist jeder Knoten mit den Knoten der nächsten Schicht verbunden, bis hin zur "Ausgabeschicht", die letztlich das Ergebnis der Vorhersage liefert7.
Eine beispielhafte CNN-Architektur ist in der folgenden Abbildung dargestelt (eigene Darstellung).

Forschungsansatz & Beitrag: Die hier dargestellten Inhalte sind zusammengefasst; alle Details finden sich im veröffentlichten Paper. Unser Forschungsbeitrag lässt sich in drei Teile gliedern:
-
Kohorten-Auswahl: Der MIMIC-IV Datensatz umfasst eine breite Vielfalt an PatientInnen. Für unser Paper haben wir uns auf die Vorhersage des Entlassungsortes bei Herzinsuffizienz-PatientInnen konzentriert. Herzinsuffizienz wird definiert als "ein komplexes klinisches System, das aus jeglicher strukturellen oder funktionalen Herzstörung resultieren kann, welche die Fähigkeit der Herzkammer beeinträchtigt sich zu füllen der Blut abzugeben"8. Die Kohorte für unsere Analyse wurde anhand der Diagnose und der DRG des Krankenhausaufenthalts identifiziert, um jene Fälle auszuwählen, in denen Herzinsuffizienz behandelt wurde. Da der Datensatz Diagnosen in Form von ICD-Codes enthält, wurden alle PatientInnen ausgewählt, deren primäre Diagnose einem Herzinsuffizienz-bezogenen ICD-Code entspricht.
-
Feature Auswahl und Datenvorverarbeitung: Die vorhandenen Rohdaten mussten so vorverarbeitet werden, dass sie von den KI Modellen die wir im nächsten Schritt verwenden wollen, verarbeitet werden können. Beispielsweise wurden kategorische Merkmale wie besuchte Abteilungen, Geschlecht oder Familienstand per One-Hot Encoding in numerische Repräsentationen überführt. Einerseits erlaubt das die Weiterverarbeitung durch Machine-Learning Modelle, aber auch, dass keine künstliche Reihenfolge zwischen den Kategorien entsteht. Zudem wurden alle numerischen Features standardisiert (auf einen Mittelwert von 0 und Standardabweichung von 1 skaliert).
-
Modellauswahl- und Training: Als Modellarchitektur wählten wir Convolutional Neural Networks (CNNs) und trainiert diese auf den vorverarbeiteten Daten zur Klassifikation des Entlassungsortes. Wir haben zudem weitere Modelltypen wie LSTMs und XGBoost evaluiert; CNNs erzielten jedoch die besten Ergebnisse für dieses Problem/Datensatz. Wir haben zudem weitere Modelltypen wie LSTMs und XGBoost evaluiert; CNNs erzielten jedoch die besten Ergebnisse für dieses Problem/für diesen Datensatz.
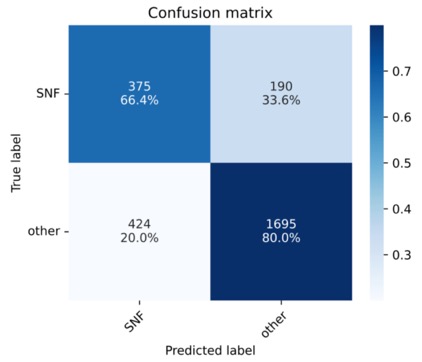
Um das besten Modell zu finden, führten wir Hyperparameter-Training durch und variierten dabei unter anderem die Kernelgrößen der Convolutional Layer, die Größe der Fully-Connected- und Pooling-Layer sowie die verwendete Aktivierungsfunktion. Die besten Modelle wurden anhand des F1-Scores ausgewählt auf einem Validierung-Teil des Datensatzes. Die finale Bewertung erfolgte anhand von Accuracy, Precision und Recall und Konfusionsionsmatrizen auf dem Test Datensatz.
Ergebnis: Der Code zu unserem Paper & zur Reproduktion der Ergebnisse findet sich auf GitHub. Bitte beachten: aufgrund von Datenschutzbestimmungen für die MIMIC-IV-Datenbank ist ein eigener Zugang erforderlich.
Das finale CNN-Modell erreicht eine Accuracy von 77%, eine gewichtete Precision von 81% und einen gewichteten Recall von 77%. Der F1-Score liegt bei 0,78, der AUROC bei 0,73.
Das folgende Diagramm zeigt die Feature-Importance unseres Modells als Beeswarm-Plot auf Basis von SHAP-Werten (SHapley Additive exPlanations)9. Der Plot wurde mit der SHAP Python-Bibliothek erzeugt und zeigt die 18 Features mit dem größten Einfuss auf den Entlassungsort (bezogen auf unser CNN-Modell). Jeder Punkt auf dem Beeswarm-Plot steht für einen einzelnen Krankenhausaufenthalt. Die x-Achse zeigt den Einfluss des jeweiligen Features an: stark negative Werte deuten auf einen hohen Einfluss zugunsten einer Entlassung in eine SNF (Skilled Nursing Facility, also eine Pflegeeinrichtung mit erhöhter medizinischer Betreuung), während stark positive Werte auf eine Entlassung in eine der anderen möglichen Entlassungsorte hindeutet. Die Farbe der Punkte zeigt den Feature-Wert (rot für hohe Werte, blau für niedrige). Da unsere Daten eine dreidimensionale Struktur hatten, die in diesem Plot nicht direkt darstellbar war, wurden die SHAP-Werte und die Featurewerte für jeden Aufenthalt gemittelt.
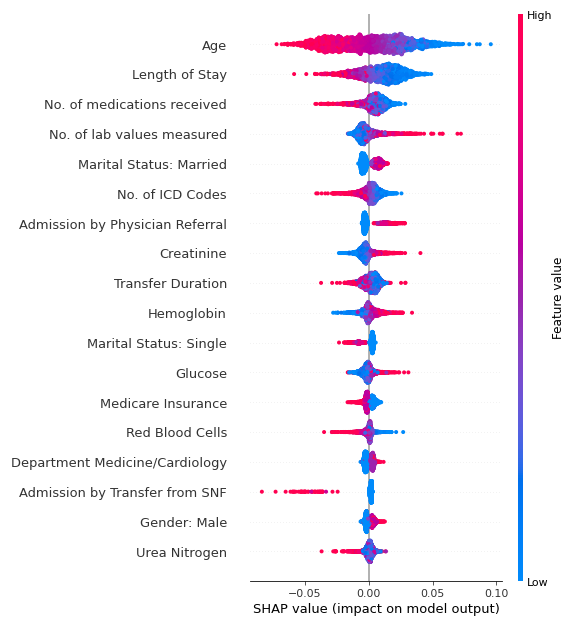
Zum Beispiel zeigt die Verteilung der Punkte für das Patientenalter, dass ein höheres Alter häufig als Prädikator für eine Entlassung in eine SNF (Skilled Nursing Facility) dient.
Diskussion und Ausblick:
- Die Einbeziehung des Behandlungsprozesses verbessert die Vorhersageergebnisse: Unsere Analyse legt nahe, dass der Behandlungsprozess bei der Klassifikation des Entlassungsortes von Herzinsuffizienz-PatientInnen berücksichtigt werden sollte. Die Analyse der Feature-Importance zeigt, dass Merkmale, die sich im Verlauf des Krankenhausaufenthaltes verändern, einen signifikanten Einfluss auf die Vorhersage des Entlassungsortes haben.
- Bestätigung relevanter Einflussfaktoren auf die Entlassungsvorhersage: Darüber hinaus konnten wir mehrere Faktoren und deren Relevanz für die Entlassungsvorhersage bestätigen, die bereits in der aktuellen Literatur erwäht werden - darunter Alter, Verischerungsstaturs, Aufenthaltsdauer, Geschlecht sowie Laborwerte (Kreatinin, Harnstickstoff und Hämoglobin). Informationen zur Verfügbarkeit informeller Pflegepersonen werden im MIMIC-IV Datensatz durch den Familienstand abgebildet. Das gilt in der Literatur ebenfalls als relevanter Faktor10. Natürlich stellt der Familienstand lediglich einen Indikator dar und garantiert nicht tatsächlich die Verfügbarkeit einer informellen Pflegeperson.
- Weitere Merkmale zum Krankenhausaufenthalt: Für zukünftige Arbeiten könnte eine detaillierte Betrachtung des Behandlungsprozesses die Modellergebnisse verbessern. In unserem Ansatz wurden Beispielsweise Diagnosen, Medikamente und Laborwerte und durchgeführte Prozeduren nicht umfassend berücksichtigt (so zum Beispiel nicht jede Veränderungn während des Krankenhausaufenthaltes). Zusätzlich könnten Informationen zur mentalen Gesundheit und weitere soziodemographische Merkmale die Ergebnisse weiter verbessern.
- Größere Stichprobe: Wir nehmen an, dass sich bei einer größeren Stichprobe (als mit dem MIMIC-IV Datensatz verfügbar) weitere Qualitätsverbesserungen erzielen lassen (da eine ausreichend große Datenbasis einen erheblichen Einfluss auf die Leistungsfähigkeit von Machine-Learning-Modellen haben kann4.
Konferenz und Publikation: Unser Forschungsbeitrag ist öffentlich zugänglich im Buch Process Mining Workshops (ICPM: International Conference on Process Mining) veröffentlicht bei Springer. Zudem ist das Paper auf ResearchGate verfügbar. Wir hatten zudem die Möglichkeit, unsere Forschung und das Paper auf der International Conference on Process Mining 2021 an der TU Eindhoven (Niederlande) Oktober 2021 zu präsentieren.
Footnotes
-
Johnson, A., Bulgarelli, L., Pollard, T., Horng, S., Celi, L., & Mark, R. (2020). MIMIC IV (version 0.4). PhysioNet. ↩
-
Weske, M. (2019). Business Process Management: Concepts, Languages, Architectures. Springer. ↩
-
Teinemaa, I., Dumas, M., Rosa, M., & Maggi, F. (2019). Outcome-oriented predictive process monitoring: Review and benchmark. ACM Transactions on Knowledge Discovery from Data (TKDD), 13(2), 1–57. ↩
-
Weytjens, H., & De Weerdt, J. (2020). Process Outcome Prediction: CNN vs. LSTM (with Attention). In International Conference on Business Process Management (pp. 321–333). ↩ ↩2 ↩3
-
Leontjeva, A., & Kuzovkin, I. (2016). Combining Static and Dynamic Features for Multivariate Sequence Classification. ↩
-
S. Weinzierl, S. Zilker, J. Brunk, K. Revoredo, A. Nguyen, M. Matzner, J. Becker, & B. Eskofier. (2020). An empirical comparison of deep-neural-network architectures for next activity prediction using context-enriched process event logs. ↩
-
Albawi, S., Mohammed, T., & Al-Zawi, S. (2017). Understanding of a convolutional neural network. In 2017 International Conference on Engineering and Technology (ICET) (pp. 1-6). ↩
-
Roger, V. (2013). Epidemiology of heart failure. Circulation research, 113(6), 646–659. ↩
-
Lundberg, S., & Lee, S.I. (2017). A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems 30 (pp. 4765–4774). Curran Associates, Inc. ↩
-
Allen, L., Hernandez, A., Peterson, E., Curtis, L., Dai, D., Masoudi, F., Bhatt, D., Heidenreich, P., & Fonarow, G. (2011). Discharge to a skilled nursing facility and subsequent clinical outcomes among older patients hospitalized for heart failure. Circulation: Heart Failure, 4(3), 293–300. ↩